1c xml based on xsd schema example. A brief description of creating an XML file using the XSD scheme using the example of creating an upload of Statistical Reporting for the Federal Customs Service. Adding an XDTO package
Annotation: XML Data Schemas (XSD). Creating an XSD schema in Visual Studio .NET. Creating a typed DataSet object. Obtaining information about the structure of a DataSet object. Loading XML documents and XSD schemas into typed and regular DataSet objects. ReadXml and ReadXmlSchema methods. Recording the content and structure of a typed and regular DataSet object. WriteXml and WriteXmlSchema methods
Typed DataSet object. Reading and writing XML documents
XML Data Schemas (XSD)
Data schemas 1 Exact translation of XML Schema Document -< XML document schema>, however we will continue to use the term "XML data schema". XSD (XML Schema Document, XSD) are an alternative way of constructing rules for XML documents. Compared to DTDs, schemas are more powerful for defining complex data structures, provide a clearer way to describe the grammar of a language, and can be easily modernized and extended. An XSD schema can contain the following information:
- representation of relationships between data elements, similar to foreign key relationships between tables in a relational database;
- representation of unique identifiers similar to a primary key;
- type specification data for each individual element and attribute in an XML document.
To create a data schema in Visual Studio .NET, go to File\New\File in the main menu and select XML Schema from the list of templates (see Fig. 11.3). A window appears that says “To get started, drag objects from the Server Explorer or Toolbox window onto the workspace (design area) or right-click” (Figure 11.1):
Rice. 11.1.
The point is that we are in design mode. Switch to code mode by clicking on the button (XML):
The first line is the familiar indication that the schema is an XML document with a root element xs:schema . The xs prefix: prefixes all schema elements to indicate its namespace. The second line contains a long, detailed and often completely unnecessary description of the schema (compare with similar code for HTML pages). For correct operation, it is enough to limit ourselves to the following representation:
However, the studio's built-in visualization tools assume the presence of this “header”, so it should not be removed. Creating a schema that describes a given XML document in Visual Studio .NET is a fairly simple task. Let's create the following XMLEasy.xml document:
We switch to the (Data) tab and see only one entry (Fig. 11.2).

Rice. 11.2.
You can create a schema that describes this document in several ways: in the main menu, select the “XML \ Create Schema” item (Fig. 11.3, A), in XML mode, select the same item in the context menu (Fig. 11.3, B), in XML mode, select the same item in the context menu (Fig. 11.3, B), in Data, select this item in the context menu (Fig. 11.3, C), and finally, in Data mode, click on the XML toolbar button (Fig. 11.3, D).

Rice. 11.3.
In any case, the document outline appears in the form of a table (Fig. 11.4). Let's leave Schema mode for now and switch to (XML) mode.

Rice. 11.4.
The environment generated XML code describing the structure of the document:
This also includes the description needed to further manipulate the schema using ADO .NET objects. In the source XMLEasy.xml document, a link to the data schema appeared:
The XMLEasy.xsd document was automatically created in the same directory where XMLEasy.xml is located.
In order to learn to understand XSD schemas, you should first work with the description of the data in its pure form, without additional elements. Table 11.1 shows several simple XML documents and their schemas, generated without binding to ADO .NET objects.
| Contents of the XML document | XSD Schema Contents |
|---|---|
|
|
|
| Description | |
| In an XMLEasy.xml document, the TOUR element is the root element containing the IDTOUR child element. The general scheme for the root element is as follows: |
|
| Contents of the XML document | XSD Schema Contents |
|
|
|
| Description | |
| The root TABLE element contains a TOUR element, which in turn consists of a group of child elements. The choice element controls the selection of other elements, with the "unbounded" value of the maxOccurs attribute indicating that TOUR groups can be unlimited. |
|
| Contents of the XML document | XSD Schema Contents |
|
|
Rice. 11.5. |
| Description | |
| The IDTOUR element's data type was set to int , the CLOSED element's data type was set to boolean , and the rest were set to the default string data type. You can change the data type directly in the XML data schema mode, but it is more convenient to use the Schema mode (in this case the mode will be called DataSet) select the data type from the drop-down list (Fig. 11.5): | |

In the course software you will find all the files for this table in the XSD folder (Code\Glava5\XSD).
Setting a data type in an XML document (Table 11.1 is the latest example) is one way to limit the content. Additional attributes are used to constrain the value of a given type. In the following schema fragment, the value of the PRICE element must be between 50 and 100:
To limit an XML document to some fixed values, use the following construct:
Here the NAME element can take only one fixed value out of five country names.
Developing an XSD schema is quite a lot of work. The visual tools in Visual Studio .NET make this task much easier. To master the basic concepts, it is advisable to learn several automatically generated XML document schemas. Tables 11.2-11.4 provide a description of the main elements and attributes that can be encountered.
| Element | Description |
|---|---|
| all | Nested elements can be defined in any order |
| annotation | Parent element of comment elements |
| any | Any nested elements |
| anyAttribute | Any attributes |
| appInfo | Comment element. Specifies the schema title |
| attribute | Attribute |
| attributeGroup | Attribute group |
| choice | Selecting other elements. Analogue of the operator "|" in DTD |
| complexContent | Restrictions or model extensions complex content type |
| complexType | Complex element |
| documentation | Comment element. Provides information about the schema |
| element | Element |
| extension | Element extensions |
| field | Field declaration. Applies inside an element |
| group | Group of elements |
| import | Importing a type declaration from another schema |
| include | Including a different schema in an existing namespace |
| key | Specifying an element or attribute with a key pointing to another element |
| keyref | Specifying the element or attribute that the key points to |
| list | An element that can contain a list of values |
| redefine | Overriding already declared elements |
| restriction | Element constraint |
| schema | Schema root element |
| selector | Selector for selecting XML elements |
| sequence | Sequence of other elements. Analog of operator "," in DTD |
| simpleContent | A model whose contents represent only character data |
| simpleType | Simple element |
| union | An element or attribute that can have multiple meanings |
| unique | An element or attribute that must have a unique value |
| Attribute | Description |
|---|---|
| enumeration List of values | |
| length | Length |
| maxLength | Maximum length |
| minLength | Minimum length |
| maxExclusive | Maximum value |
| maxInclusive | Maximum value inclusive |
| minExclusive | Minimum value |
| minInclusive | Minimum value inclusive |
| fractionDigits | Number of decimal places in fractional numbers |
| totalDigits | Number of digits |
| pattern | Sample (pattern) of element contents |
| default | Default element or attribute value |
| elementFormDefault | Setting properties of a local element as globally defined |
| fixed | Fixed element or attribute value |
| form | Locally declared elements are defined in specific document instances |
| itemType | List Item Type |
| memberTypes | Type of members used in union |
| maxOccurs | Maximum number of occurrences of an element |
| minOccurs | Minimum number of occurrences of an element |
| mixed | Specifying an element that has a mixed type |
| name | Element or attribute name |
| namespace | Namespace |
| noNamespace | Specifying the location of the schematic document, |
| SchemaLocation | having no resulting namespaces |
| nillable | Determining that an element can have an empty NULL value (nil) |
| ref | Setting a reference to a globally defined element |
| schemaLocation | Locating the circuit |
| substitutionGroup | Defining the replacement of elements with other elements |
| targetNamespace | Resulting schema namespace |
| type | Item type |
| use | Is the element required or not? |
| value | Schematic element value |
| xsi:nil | Setting the actual content of an empty (NULL) element in an XML document |
| xsi:schemaLocation | The actual location of the element in the XML document |
| xsi:type | The actual type of the element in the XML document |
The task of creating an XML file based on an XSD schema appeared. Searching the forums led to a large number of discussions related to a misunderstanding of the process, and only a couple of articles explaining the essence. People asked questions, struggled with the solution, but after the problem gave in to them, they simply disappeared without describing the mechanism. This prompted the creation of a simple description of the process.
P.S. Don’t swear too much, my goal was not to create some kind of scientific article strictly using the correct terminology, but to simply help take the first step towards understanding the very powerful exchange mechanism via XML.
P.P.S. I must immediately make a reservation that the upload file attached to the article is only a template that creates only part of the required XML file structure, because my work with this download was rather educational in nature (copying the previous export document on the FCS website and downloading only the tabular part of the Products from an Excel file seemed to be a more effective solution), and the lack of time did not allow me to complete the creation of the entire structure, based only on considerations of perfectionism .
So, having registered on the FCS website, it became clear that in order to create Statistical Reporting documents on exports, it is necessary to download data from the Sales of Goods and Services Trade Management documents and create a file for downloading.
There are two possible download options.
First: loading the tabular part with Products from an Excel file (this option was chosen as a working option, because it had the advantages that there was no need to bother with processing the “Header” of the document, but you could simply copy the previous one, changing it in the “Header” "what was required).
Second: creating an XML file according to the scheme downloaded from the FCS website in the form of an “Album of formats for electronic document forms”. The album contains a fairly large number of XSD schemes. They found a diagram of the “Statistical Form for Accounting for the Movement of Goods” and additional files with descriptions of the types for it. The diagrams are attached to the article in the archive with processing.
To view XSD schemas, we used the free Microsoft XML Notepad 2007.

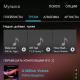
The image shows the main file with the XSD schema "Statistical form for accounting for the movement of goods." The image highlights the main blocks of the XSD scheme that we need to understand it.
From the diagram it is clear that we need to get an XML file filled with the structure specified in the "xs:element" branch of the StaticFormType type.
The structure can be quite complex (as in our case). With type descriptions present directly in the branch, placed in a separate branch, or even located in another file.

This structure has a type StaticFormType, which in turn consists of a base type BaseDocType, a set of objects of different types and text attributes.

The base type BaseDocStyle is defined in a different file (and namespace)  .
.
This file contains a lot of types that are not used in our case.
Now let's move on to working in 1C. In a nutshell, what we need to do comes down to the following:
1. XDTO Factory is being created
OurFactoryXDTO = CreateFactoryXDTO(ArrayFullFileNamesWithXSDSchemas);
2. In the XDTO factory, all complex data types are created, which we will then fill in in the created XML file:
StaticFormType = MyFactoryXDTO.Type("urn:customs.ru:Information:CustomsDocuments:StaticForm:5.4.0", "StaticFormType");
The data types included in a certain type can be obtained from the collection of its properties:
CUOrganizationType = StaticFormType.Properties.Get("Consignee").Type; NameType = CUOrganizationType.Properties.Get("OrganizationName").Type; ShortNameType = CUOrganizationType.Properties.Get("ShortName").Type; LanguageCodeType = CUOrganizationType.Properties.Get("OrganizationLanguage").Type;
3. When all complex data types have been created, we create an XML file structure based on them, consisting of XDTO Factory objects:
StaticFormType_XDTOObject = MyXDTOFactory.Create(StaticFormType); // collection with documents NewDocuments = MyFactoryXDTO.Create(DocumentsType); NewDocuments.PrDocumentName = MyFactoryXDTO.Create(PrDocumentNameType, "Waybill"); NewDocuments.PrDocumentNumber = MyFactoryXDTO.Create(PrDocumentNumberType, "123-number"); NewDocuments.PrDocumentDate = MyFactoryXDTO.Create(PrDocumentDateType, "2014-10-05"); StaticFormType_XDTO.Documents.Add(NewDocuments);
At the same time, fill in the elementary (simple types) details.
4. And finally, we unload everything from the XDTO Factory into a file:
XML File = New XML Entry(); FileXML.OpenFile(FileName); XML File.WriteXML Declaration(); MyXDTOFactory.WriteXML(XMLFile, StaticFormType_XDTOObject); FileXML.Close();
P.S. The archive contains an upload template file in XML (only some details are created, reflecting all cases where the file is filled out) and XSD schemas.
Unzip all files into a certain directory.
XML will be created in it.
The XML format is very popular when exchanging various text documents between information systems. The ability to create a unique structure for documents allows it to be used in many areas - electronic libraries, WEB, import/export, and many others. Without the ability to conveniently work with this format, 1C systems would not have gained such popularity. Since 1C actively uses WEB technologies, every developer must be able to read XML and write information into it.
XML File Representation and Reading
One of the key advantages of the XML markup language is its fairly convenient and intuitive structure and syntax. When creating it, the authors set a goal to create a markup language that would be easy to read by both humans and computers. Today, XML has been widely developed into other formats, but remains popular and widely used. The structure of the XML file is built according to the following scheme:
To consider an example of importing data into 1C, the file presented above will be sufficient. In order for the written procedure to be able to read the XML file, it is enough to pass the path to the file itself into it. This can be done through the interface, allowing users to specify the file themselves, or by hard-coded processing in the text.
One of the popular ways to work with XML up to 100 MB in size in 1C is to use the Document Object Model (DOM). Its meaning is to sequentially process all document nodes represented in XML. In the built-in 1C language, this algorithm looks like this:
- Declaration of the mechanisms by which the XML file is read; Loop to traverse nodes;
- Reading data and attributes in a node;
- Information output. If necessary, at this stage writing can occur in variables or directly in the necessary tables;
- Completion of the mechanism.
As a result, we display messages to the user with the imported data. You can also place all the data in the desired structure and, based on it, program the creation of a document or entries in the directory. The speed of 1C work with xml is quite high, so this format is increasingly used when exchanging data with other sources.
To upload information, we will also need to interact with XML files. Let's look at an example of a record using the 1C platform object XML Record and upload data on the item. Its main advantages are the simplicity of the code and the speed of data processing. The server-side algorithm for writing an XML file can be represented as several sequential steps:
- Connect to the xml file;
- We create head elements and write data to them. If you want to upload a large amount of information into an XML file, then at this stage you will use loops. Be careful and remember that the data request must be made before the loop, and not in it;
- Close the file.
XDTO mechanism in 1C
1C company developers have created their own mechanism for exchanging information via XML - XDTO (XML Data Transfer Objects). Starting from version 8.1, the platform has the ability to exchange data with other systems without delving into the issues of generating an XML file. Most technical issues are taken care of by 1C, and all we have to do is indicate the data necessary to generate XML. True, for this the developer needs to do some manipulations in advance.
To load an XML file using XDTO, we must tell 1C the structure of the file. It is transmitted through a set of diagrams that can be created in a text editor or using a specialized program. The resulting file should describe the general structure and data types used in the XML file. Before reading or writing new XML, the developer must load its schema into the configuration under XDTO Packages.
In this case, we will create a simple package by hand so that 1C understands the structure of our example file. In order for the file generation to complete successfully, we need to reflect in the schema that we have a head element and an attachment with attributes. The created schema must be exported to a file in xsd format and transferred along with xml, so that the other party does not need to deal with the structure and create the xdto package again.

A server algorithm similar to the previous one will help you save the new XML to your hard drive. The only difference is the need to add data for 1 product to the XDTO factory - a special mechanism of the 8.3 1C platform. If there is a need to create more nesting levels, you will have to describe each head element.
//Open the XML file RecordVFile = New RecordXML; WriteToFile.OpenFile("D:\Nomenclatura.xml", "UTF-8"); //Indicate to 1C what type of data should be created - head element AllProducts = FactoryXDTO.Create(FactoryXDTO.Type("http://wiseadviceXML.org","Products")); //select data for uploading SelectionFromDirectory = Directories.Nomenclature.Select(); //Add individual products to the head element While Select from the Directory.Next() cycle Product = FactoryXDTO.Create(FactoryXDTO.Type("http://wiseadviceXML.org","Product")); Product.Name = Select from the Directory.Name; Product.InitialPrice = String(SelectionFromDirectory.InitialPrice); AllProducts.Add(Product); EndCycle; //write the data and close the file FactoryXDTO.WriteXML(WriteToFile, AllProducts); WriteInFile.Close();The mechanisms considered are quite universal and, if properly configured, can solve most problems. However, there are quite a lot of nuances in the interaction between 1C and XML. It is much more effective to study them in real conditions, and not on test tasks in which processing an XML file solves rather narrow problems.
This chapter will show you how to write XML schemas. You will also learn that the diagram can be written in different ways.
XML Document
Let's look at this XML document called "shiporder.xml":
xsi:noNamespaceSchemaLocation="shiporder.xsd">
Langgt 23
The XML document above consists of a root element, "shiporder", which contains a required attribute called "orderid". The "shiporder" element contains three different child elements: "orderperson" , "shipto" and "item" . The "item" element appears twice, and it contains a "title" element, an optional "note" element, a "quantity" element, and a "price" element.
The line above: Xmlns: XSI="http://www.w3.org/2001/XMLSchema-instance" tells the XML parser that this document should be schema validated. Line: XSI: noNamespaceSchemaLocation = "shiporder.xsd" indicates where the schematics are located (here it is in the same folder as "shiporder.xml") .
Creating an XML Schema
Now we want to create a schema for the XML document above.
We'll start by opening a new file, which we'll call "shiporder.xsd". To create a schema we could simply follow the structure in the XML document and define each element as we find it. We'll start with a standard XML declaration followed by an xs:schema element that defines the schema:
...
In the schema above we are using standard namespaces (xs), and the URI associated with this namespace is the schema language definition, which has the standard value http://www.w3.org/2001/XMLSchema.
Next, we need to define a "shiporder" element. This element has an attribute and contains other elements, so we treat it as a complex type. Child elements of a "shiporder" element are surrounded by an xs: sequence element that defines an ordered sequence of subelements:
...
Then we must define the "orderperson" element as a simple type (since it does not contain any attributes or other elements). The type (xs:string) is prefixed with a namespace prefix associated with the XML Schema, which specifies a predefined schema data type:
With the help of schemes we can determine the number of possible occurrences for an element with MaxOccurs and MinOccurs attributes. MaxOccurs specifies the maximum number of occurrences for an element and MinOccurs specifies the minimum number of occurrences for an element. The default value for both MaxOccurs and MinOccurs is 1!
Now we can define the "item" element. This element may appear multiple times within a "shiporder" element. This is determined by setting the maxOccurs attribute of the "item" element to "unbounded" , which means that there can be as many occurrences of the "item" element as the author wants. Note that the "note" element is optional. We defined this by setting the minOccurs attribute to zero:
Now we can declare the "shiporder" attribute of the element. Since this is a required attribute we specify use="required".
Note: Attribute statements must always come last:
Here is a complete list of the schema file called "shiporder.xsd":
Separate circuits
The previous design method is very simple, but can be difficult to read and maintain when the documents are complex.
The next design method is based on defining all elements and attributes and then referencing them using the ref attribute.
Here is the new design of the schematic file ("shiporder.xsd"):
Using Named Types
The third design method defines classes or types, which allows element definitions to be reused. This is done by naming the elements simpleTypes and complexTypes, and then referring to them through the element's type attribute.
Here is the third design of the schematic file ("shiporder.xsd"):
The constraint element indicates that the data type was derived from the W3C XML Schema data type namespace. So the following snippet means that the value of the element or attribute must be the value of a string:
The constraint element is more often used to apply restrictions to elements. Look at the following lines from the above diagram:
This specifies that the value of the element or attribute must be a string, it must be exactly six characters per line, and those characters must be a number between 0 and 9.
XDTO is a 1C mechanism that is needed when creating and using web services in 1C.
XDTO 1C packages allow you to describe the structure of the required XML file for converting data to and from XML.
For those interested, let's look at the question in more detail.
XML files are transmitted over the Internet and can be read by many programs.
They are perceived - that means it is hardwired into their code - if you come across a certain element name in the XML file - perceive it like this and do this.
Therefore, if we use the element name Apple, then there is a fairly high chance that some other program may “think” that this is the Apple it knows, but we meant something of our own.
To prevent this from happening and to clearly indicate that our Apple is different from all others, the name of the namespace can be specified in the file - a prefix that is used before the name of the elements.
The namespace (in English namespace) is defined like this - xmlns:SpaceName = “URL”, for example:
xmlns:store = "http://store.ru"
Why do you need a URL?
Therefore, a unique identifier is specified, which also identifies the author of the namespace.
Naturally, it is assumed that the person who indicated the namespace is an extremely honest person and indicated his site and does not use several different namespaces with one site.
By the way, they usually indicate not only the site URL, but the URL of a specific folder on the site, so that if anything happens, you can create another namespace in another folder on the site for use in a different situation.
An object is a specific data structure, self-sufficient, containing all its data.
Since structured data is described in XML, that is, in the form of a structure that has its own properties, etc., they can be looked at as objects.
In the example given, this could be a LIST object with a property and a nested element.
DOM is a way of treating an XML file not as text in a specific format, but as a collection of objects with properties, fields, and so on.
Description of the XML file
If we are using a file of a certain structure constantly to exchange between two programs, we would probably want to:
- To have certain names used
- To have those elements that we expect (which "must be there to be used in our exchange")
- So that the attributes contain the types that we expect (string, number, etc.).
The following file format standards exist to describe XML structure (which are also stored in a plain text file):
- DTD extension – Document Type Definition
- XSD extension – XML Shema.
Both formats describe what the document should be like. The procedure for checking whether XML conforms to the standard described in such a file is called verification.
XDTO 1C is a tool that allows you to add a description of an XML file to the configuration. Or rather, it is not the file that is described, but specific XML structures.
To indicate the types that can be used, a list or a type library is used, which is called the XDTO 1C factory.
This factory specifies both simple types (string, number, date), which are commonly used in other languages, programs, etc., but also 1C types, which are used in 1C and in a specific configuration.
The XDTO 1C factory itself consists of several packages. The basic types are described in a package called www.w3.org
Current configuration data types are described in the package http://v8.1c.ru/8.1/data/enterprise/current-config
The types themselves are named according to the name in the configurator with the addition of an English-language form (CatalogRef, CatalogObject, DocumentRef, DocumentObject), for example:
CatalogObject.Nomenclature
Adding the XDTO 1C package
This all certainly sounds cool. And we haven't gotten to the topic of XSLT yet - a way to transform XML files into something else, such as HTML. The topic of XML is extremely large and difficult to cover even in a separate book.
Our task is to understand that XDTO 1C allows us to describe what elements an XML package that needs to be generated or read should have.
XDTO 1C packages are located in the configuration in the General/XDTO 1C Packages branch.
You can add the XDTO package to 1C manually (cool!), but it is better to get the corresponding XSD file with a ready-made description of the scheme.
A description of the XSD schema for objects of any configuration can be obtained by clicking on the General/XDTO 1C Packages branch and selecting the menu item Export XML configuration schema.
The file is text, you can edit it in Windows Notepad, removing unnecessary objects that you do not need.
You can add a ready-made XSD schema to 1C by right-clicking on the General/XDTO 1C packages branch and selecting the Import XML Schema menu item.
Using the XDTO 1C mechanism
Working with XDTO 1C means converting values to and from XML.
The work is carried out using 1C language objects Reading XML/Writing XML.
When working with the XDTO 1C mechanism, you must indicate the package you are working with. This can be a standard package (discussed above, see XDTO) or a package added to the configuration. The package is identified by the URL specified in the package.
The two main simple ways to work are:
- Serialization - automatic conversion of values from 1C to XML and vice versa
- Creating an object, filling in its fields, writing to XML (and, accordingly, reading from XML and then reading its fields).
Example of value serialization:
Serializer = New SerializerXDTO(FactoryXDTO);
XML File = New XML Entry();
FileXML.OpenFile("FileName");
Serializer.WriteXML(XMLFile, Value1C);
Example of reading/writing an object:
DirectoryObjectXDTO = FactoryXDTO.Create(FactoryXDTO.Type("http://v8.1c.ru/8.1/data/enterprise/current-config", "CatalogObject.Warehouses"));
FillPropertyValues(DirectoryObjectXDTO, DirectoryLink1C);